メンタルの状態を自動で判定してくれる打刻ウェブアプリを作りました!
はじめに
3ヶ月前ぐらいから作ってきたものをようやく数日前にリリースすることができたので、今回はそのリリースしたものについてご紹介したいと思います。
今まではどちらかというとユーザーのPCで動かすためのアプリケーションを中心に作って来たわけですが、今回のものはブラウザからアクセスして利用するウェブアプリです!
↓作ったやつ
詳しい説明
アプリケーション名
リポジトリ名にもある通り、作ったウェブアプリの名前は「マイマネージャー」です。この名前には「私(のための)マネージャー」という意味を込めています。
機能
一般的な勤怠管理システムにあるような機能(打刻、自分の出席記録の確認、CSVファイルへの記録のエクスポート)に加え、以下の機能を搭載しています。
Airtableとの連携
ノーコードで視覚的・直感的にデータベースを扱うことができるウェブサービス「Airtable」との連携に対応しています。従来の行と列だけの殺風景で非生産的なデータ分析とはおさらばしましょう!
あのNetflixも社内で使っているというAirtableの詳細はこちら(ステマではないです)。
打刻の際にメンタルの状態を自動で判定
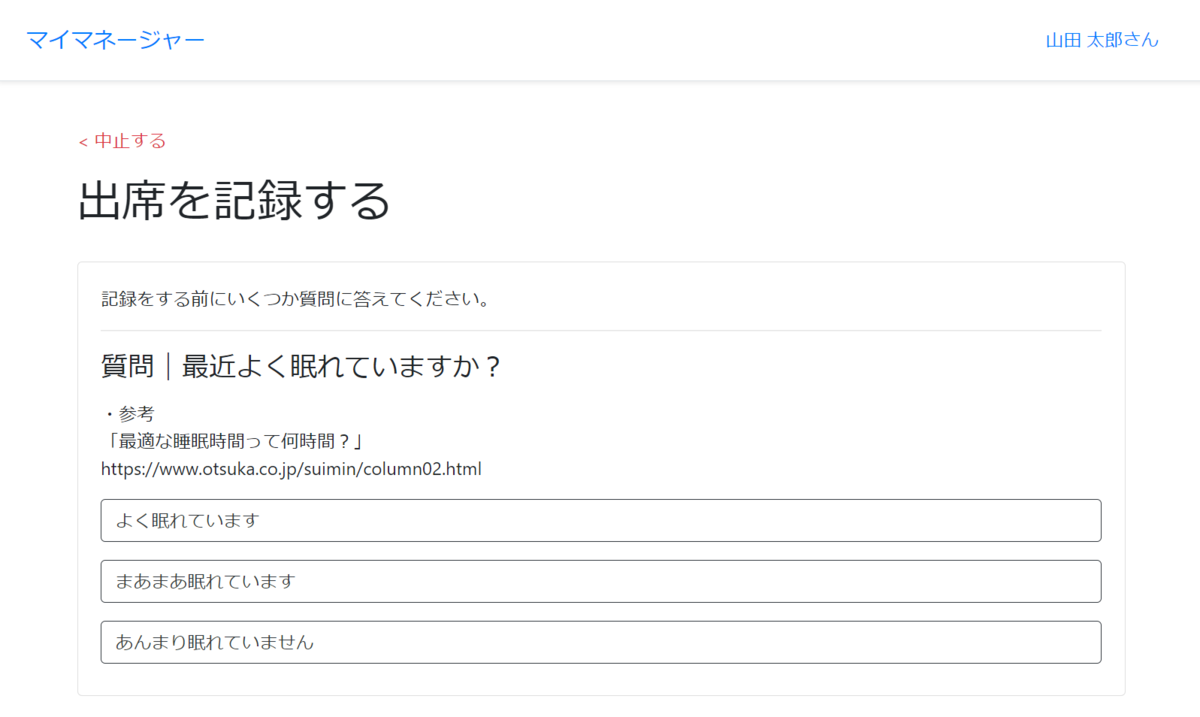
システムにあらかじめ質問と選択肢を登録しておくと、打刻の際にシステムが自動でユーザーのメンタルコンディションを判定します(選んだ選択肢の内容と回答までにかかった時間を基に計算します*1)。判定結果はメンタルスコアとして数値化され、ユーザー及び管理者はいつでも記録を確認することができます。*2
*1 回答時間は過去にその同じ質問に回答したユーザーが要した時間に基づいてスコア化されます。回答時間が上位25%に含まれる場合は2、上位26%~75%に含まれる場合は1、それらに含まれない場合は0に変換されます(この基準は四分位数の形式でカスタマイズすることができます)。
*2 メンタルスコアの計算に使用される選択式質問の回答データは記録されません(プライバシー保護のため)。
出席データとメンタルデータを基にユーザーごとのレポートを提供
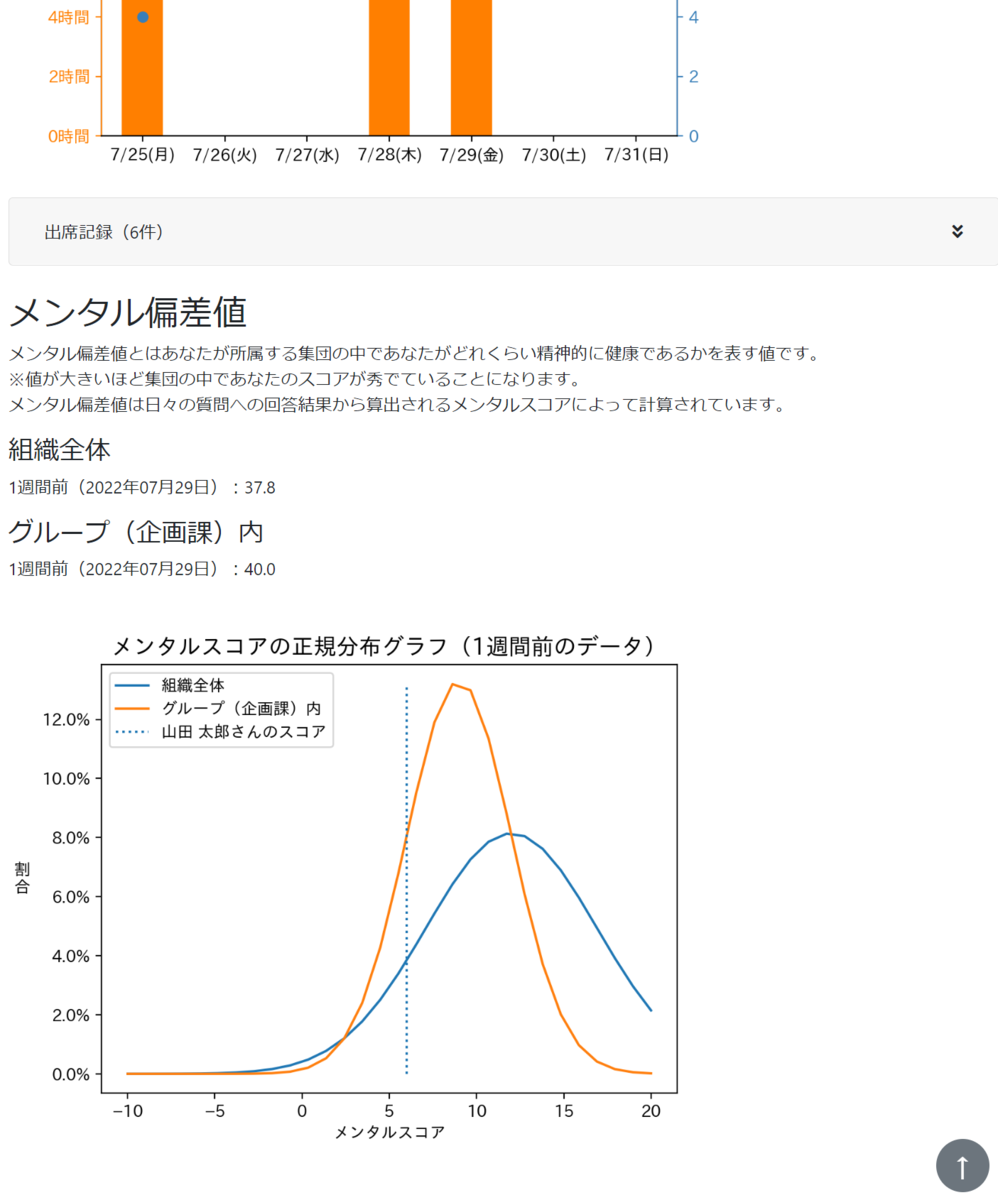
システムに記録された出席データとメンタルデータを基にユーザーに自分だけのレポート(マイレポート)を提供します。マイレポートには各データを総合してのメンタルコンディションの評価、先週の各曜日毎の作業時間及びメンタルスコア、組織全体及び所属するグループ内でのメンタル偏差値が記載されています。また、このレポートは毎日更新されます。
レポートで日々の生活状況をデータとして確認することで、過労によって無意識のうちにメンタルを壊してしまうようなことを防止できます。
PC用拡張機能と連携して打刻忘れを防止

このウェブアプリにはWeb APIの機能も含まれています。
そして、そのAPIを利用したマイマネージャー用拡張機能を開発しました!名前は「My Manager Extension」です(そのままですね...)。
機能としてはウェブアプリの各機能へのショートカット、打刻を忘れている場合のリマインダー、一定時間が経過した際の休憩リマインダーなどがあります。
ちなみにWindows専用です。
使い方
①使用するアプリケーションに適用される全てのライセンス(MIT Licenseなど)を確認する
↓同意する場合
②使用するアプリケーションのREADMEファイルに書いてある通りにセットアップをする
※今回はREADMEファイルを日本語で書いたので、詳細は省略します。
余談
今回のアプリ開発は、テレビを見ていた時に仕事でメンタルを壊してしまった人の映像と勤怠管理システムのCMがあまり間を空けずに流れたことでとっさにひらめいたことをきっかけとして始めました。
なのでこれらのアプリは自分の所属する組織がメンタルヘルスについての取り組みを行っていない人にこそ使ってほしいわけですが、実際にはそういう人ほどアプリを使って記録を残すなんてことには消極的だったりするわけです(目の前の作業に追われていたりするので)。
そのような人に積極的に使ってもらうにはどうすればいいんでしょうか...
リンク
マイマネージャー:https://github.com/bigbamboo-jp/my-manager-ja
My Manager Extension:https://github.com/bigbamboo-jp/my-manager-extension-ja
【Python】かっこの中の文字を抜き出したり、かっこの中を除いて文字列操作をする
最近Pythonでプログラムを組んでいる時に括弧の中を除いて文字列操作をするためのライブラリがなく苦労したので、そのために書いたコードをライブラリにまとめて公開することにしました。
需要があるか微妙なライブラリなので、PyPIでの公開は保留にしています。
公開サイト
プロジェクト名:Splitable str
モジュール名:sstr
github.com
使い方
例1:文章の中でカギ括弧で囲まれている単語を抜き出す
from sstr import sstr text = 'これは「りんご」ですか?いいえ、「オレンジ」です。なら「ぶどう」をください。' text_ = sstr(text) surrounded_words = [] for part in text_.divide_and_classify(enclosure=[['「', '」']]): if part[1] == True: word = part[0] surrounded_words.append(word[1:-1]) print(surrounded_words) # ['りんご', 'オレンジ', 'ぶどう']
例2:文章の中の「日」の数を数える(ダブルクォーテーションマークで囲まれている部分は検索対象から外す)
from sstr import sstr text = '信頼できる人が"今日は晴れ"だと言っていたが、天気予報は今日・明日は雨だと言っている。' text_ = sstr(text) quantity = text_.scount('日', enclosure='"') print(quantity) # 2
その他の使用例はREADMEで確認できます。
VEGAS Proのプリセットなどを他のPCにコピーする
前置き
最近メインPCを変えました。
新しく使い始めるPCに自分がいつも使うソフトをインストールしていくのですが、中には設定の移行が必要なものもあります。
ChromeやらMicrosoft Officeなんかはアカウントと紐付いてるので自動でやってくれたりするのですが、そうでないソフトは自分で設定のエクスポート・インポートをしなければいけません。
そんな作業を眠気と闘いながらのんびりやっていると、動画編集ソフトのVEGAS Proの設定を移行するのが一筋縄ではいかないことに気づきました。
普通、動画編集ソフトなどのクリエイター向けソフトは設定の移行をするためのメニューがあったりするのですが、VEGAS Proだけはそういうのが見当たりませんでした。
仕方なくGoogle先生に聞きに行くと、「Preset Manager 2.0」というのをダウンロードするように言われました。
とはいっても、そのソフトは既に公式からの配布が終了しており、非公式のアーカイブサイトからダウンロードせざる得ない状況でした。
その時はもうクタクタだったので、ウイルスチェックだけしてそのインストーラーからソフトをインストールしました。
※良い子は怪しいサイトからプログラムをダウンロードしないように。
そしてそのソフトを使用してデータ移行をしたのですが、移行された設定はイベントFXのフィルタ パッケージだけでした。
ただそれ以外に使えそうなツールもないので、仕方がなく1時間ぐらいかけて手動で設定を移行しました。
一応今回はそれで移行が完了したのですが、数年後また同じことで苦労するのも嫌なので、設定を移行するのに必要な作業をプログラムにまとめておくことにしました。
本題
というわけで、今回はVEGAS Pro Configuration Backup Toolsをご紹介します。
このフリーソフトを使うとVEGAS Proのエフェクト設定などをバックアップ・復元できます。
バックアップ対象は「各イベントFXのフィルタ パッケージ」、「メディアジェネレータのプリセット」、「レンダリング テンプレート」です。
使い方
※プログラムを使用するにはライセンス(MIT License)への同意が必要です。
1. 最新のプログラムが入ったZIPファイルをダウンロードする
こちらのページに載っている最新のリリースの「Source code (zip)」をダウンロードしてください。
2. ZIPファイルを展開する
ダウンロードしたZIPファイルを右クリックして、「すべて展開」をクリックすると展開ウィザードが表示されます。
3. 展開したフォルダの中から自分がバックアップしたい項目のフォルダを見つける
[参考]
各イベントFXのフィルタ パッケージ → Event FX
メディアジェネレータのプリセット → OFX Presets
レンダリング テンプレート → Render Templates
4. バックアップしたい項目のフォルダ内にある「save.bat」を実行する(移行元で操作)
5. バックアップファイルを実行する(移行先で操作)
※USBメモリなどでバックアップファイルを移行先にコピーする必要があります。
注意点
1. 全ての設定が移行されるわけではありません(例えばイベント パン/クロップのプリセットは移行されません)。
2. このプログラムは自己責任で使用してください。
Cloud OCR Snipで画像ファイルから文字を読み取る方法
このページではフリーソフト「Cloud OCR Snip」で画像ファイルから文字認識する方法について説明しています。
このソフトの概要についてはこちらを、インストール・初期設定方法についてはこちらをご覧ください。
また、画面上の文字を読み取る方法についてはこちらをご覧ください。
画像ファイルから文字認識する
1. タスクトレイのアイコンを右クリックする
2. 「画像ファイルから読み取る」を左クリックする

3. 文字認識する画像を選ぶ
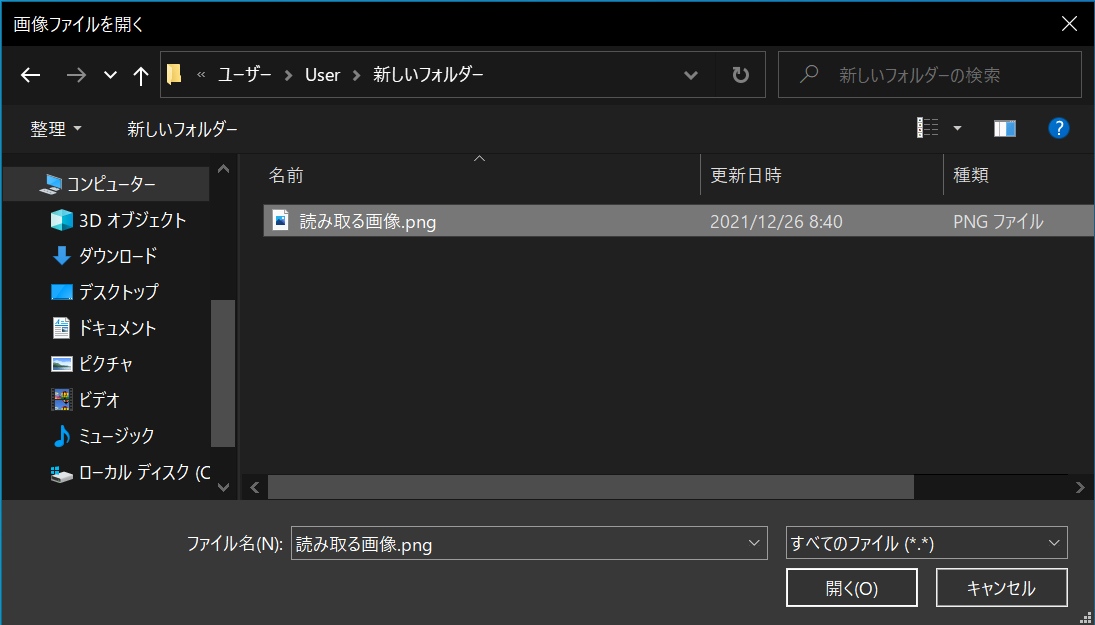
4. 文字認識完了
クリップボード上にある画像から文字認識する
文字認識の結果と読み取った画像の両方が必要な場合は、先に切り取り & スケッチでスクリーンショットを撮影してから(ショートカットキー:Windowsキー・Shiftキー・Sキー同時押し)、その画像をCloud OCR Snipで読み込みます。
※切り取り & スケッチでショートカットキーを使用してスクリーンショットを撮影すると、自動でクリップボードにコピーされます。また、撮影完了時に表示される通知をクリックすると、スクリーンショットをファイルに保存することができます。
タスクトレイのアイコンから始める場合
1. タスクトレイのアイコンを右クリックする
2. 「クリップボードの画像から読み取る」を左クリックする
※クリップボード上に読み込める画像データがない場合はクリックできません。
ショートカットキーから始める場合
1 & 2. ショートカットキーを押す
※デフォルトのショートカットキー:Windowsキー・Shiftキー・Dキー同時押し
※クリップボード上に読み込める画像データがない場合は何も起きません。
共通の手順
3. 文字認識完了
※画面上の文字を読み取る方法についてはこちらをご覧ください。
Cloud OCR SnipでPCの画面から文字を読み取る方法
このページではフリーソフト「Cloud OCR Snip」で画面上の文字を読み取る方法について説明しています。
このソフトの概要についてはこちらを、インストール・初期設定方法についてはこちらをご覧ください。
また、画像ファイルから文字認識する方法についてはこちらをご覧ください。
タスクトレイのアイコンから始める場合
1. タスクトレイのアイコンを左クリックする
ショートカットキーから始める場合
1. ショートカットキーを押す
※デフォルトのショートカットキー:Altキー・Shiftキー・Sキー同時押し
共通の手順
2. 文字認識させたい範囲で左クリックしながらドラッグする
※エスケープキーで文字認識をキャンセルできます。
3. 範囲が決まったら左クリックをやめる

4. 文字認識完了
※画像ファイルから文字認識する方法についてはこちらをご覧ください。
Cloud OCR Snipのインストール・初期設定方法
このページではフリーソフト「Cloud OCR Snip」のインストール・初期設定について説明しています。
↓のページでこのソフトの概要について説明しているので、読んでない方はぜひそちらを先にご覧ください。
インストールの流れ
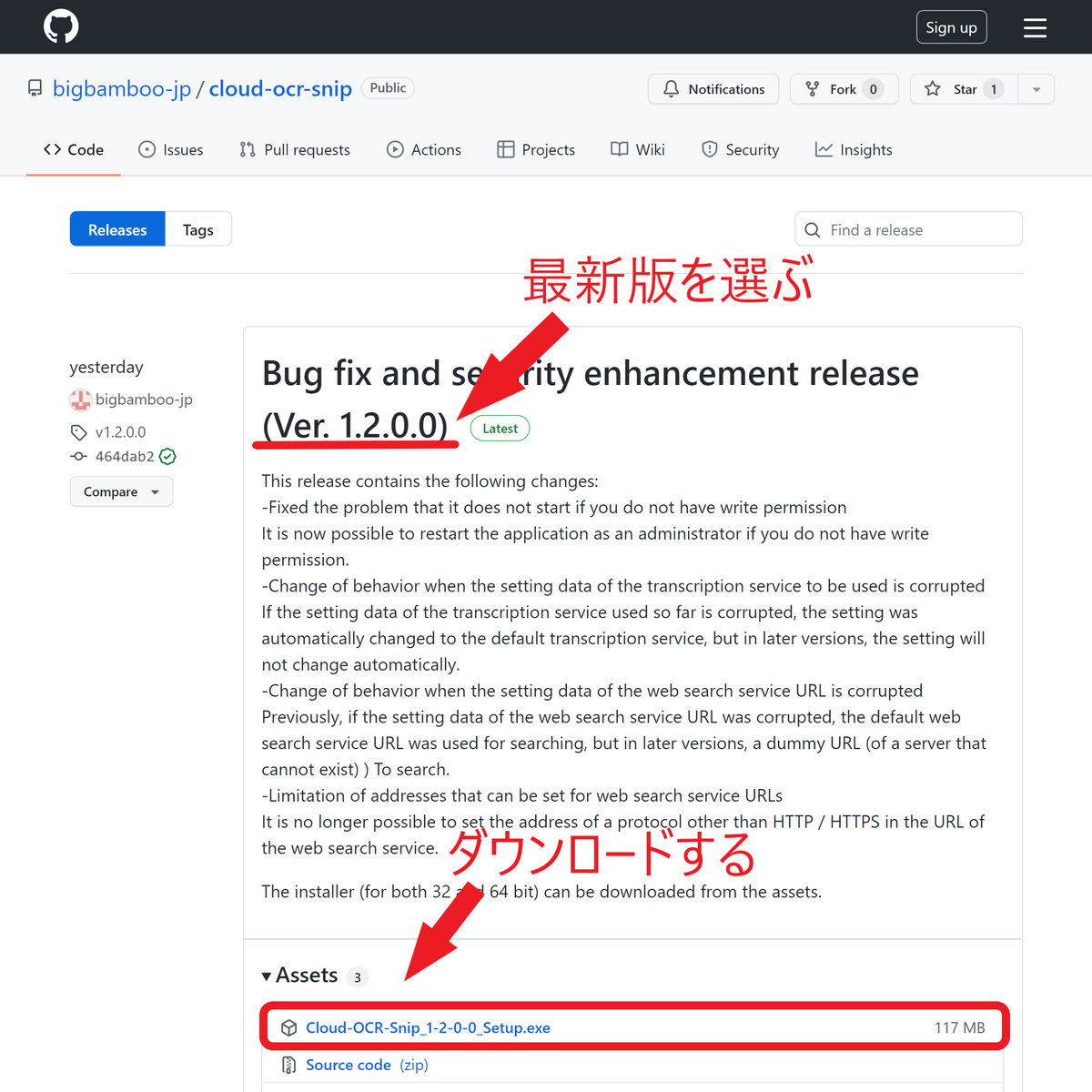
1. 最新のインストーラーをダウンロードする
配布ページはこちらです。
2. ダウンロードしたインストーラーを実行する

※ユーザーアカウント制御の画面が表示された場合は実行を許可してください。
3. 画面の指示に従ってインストールする
初期設定の流れ
通常、インストールが完了すると自動で初期設定ウィンドウが開きますが、何らかの理由で開かなかった場合は以下の操作をしてください。
スタートメニューを開く→Cloud OCR Snip フォルダを展開する→Cloud OCR Snipを実行する
※ユーザーアカウント制御画面が出た場合は実行を許可してください。
基本的には画面の指示に従っていけば初期設定を終えることができますが、クラウドサービスの設定については少し複雑なのでここで簡単に説明したいと思います。
このクラウドサービスは利用時に認証が必要であるため、事前にGoogleのサイトで登録を行っておく必要があります。
ここで説明しようかとも思いましたが、既にしっかり解説しているサイトがあったのでそちらをご覧ください。リンク先のページのjsonファイルをダウンロードするところまでの操作が必要です(ダウンロードしたファイルはソフトに登録してください)。
※設定する支払い方法はクレジットカード(デビット含む)、PayPalから選べます。
さっそく使ってみる
初期設定が終わったら、早速使ってみましょう!
※使い方は以下のページで説明しています。
画面上の文字を認識する方法:
https://bigbamboo-jp.hatenablog.com/entry/cos-introduction-3
画像ファイルから文字認識する方法:
https://bigbamboo-jp.hatenablog.com/entry/cos-introduction-4
PCの画面や画像ファイルに含まれる文字を読み取って使いたい!
PCを使っていると、たまにこんなことがあります。
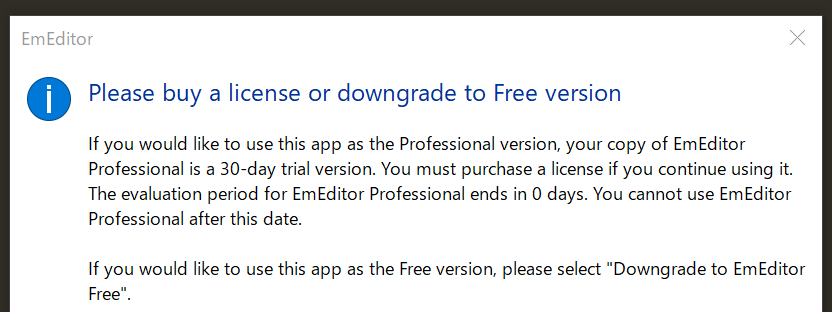
「え...なんだって?」(画像:EmEditorのメッセージダイアログ)
こんなとき、大体の人は翻訳サイトを使って意味を理解しようとします。ですが、これはメッセージダイアログです。
ドラッグして範囲選択をした後に右クリックして「コピー」をクリック... なんてことはできません。
なので、普通は翻訳サイトに手打ちで入力することになるのですが、ある程度長いテキストになってくるともう面倒くさくて仕方ないわけです。そうなると、人は楽したい生き物なので「画面上の文字をぱっと読み取る方法はないかな~」なんて考えますよね?
今回はそれを簡単に実現するソフトをご紹介したいと思います。
フリーソフト:Cloud OCR Snip
前置きが長くなりましたが、今回紹介するのは「Cloud OCR Snip」というフリーソフトです。
画面上の文字を読み取る方法は他のブログでも紹介されていたりするのですが、大体どの方法も手順が多い・認識精度が微妙などの問題を抱えています。
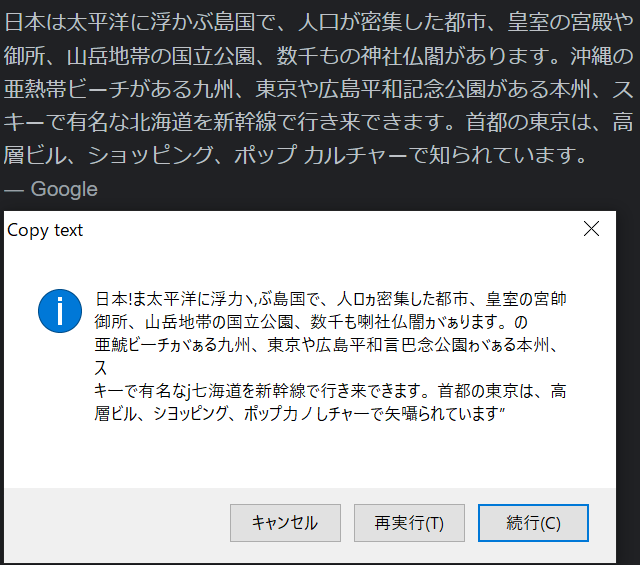
北海道=j七海道 では使い物にならない (画像:「日本」の検索結果をGT Textで文字認識させた結果)
上の画像のような認識結果を返すソフトはみんなローカルの文字認識エンジンを使用して文字認識をしています。確かに簡単な文であればそれできちんと読み取れるかもしれませんが、少し難しい文字が入ってきたりすると一気に精度が落ちてしまいます。
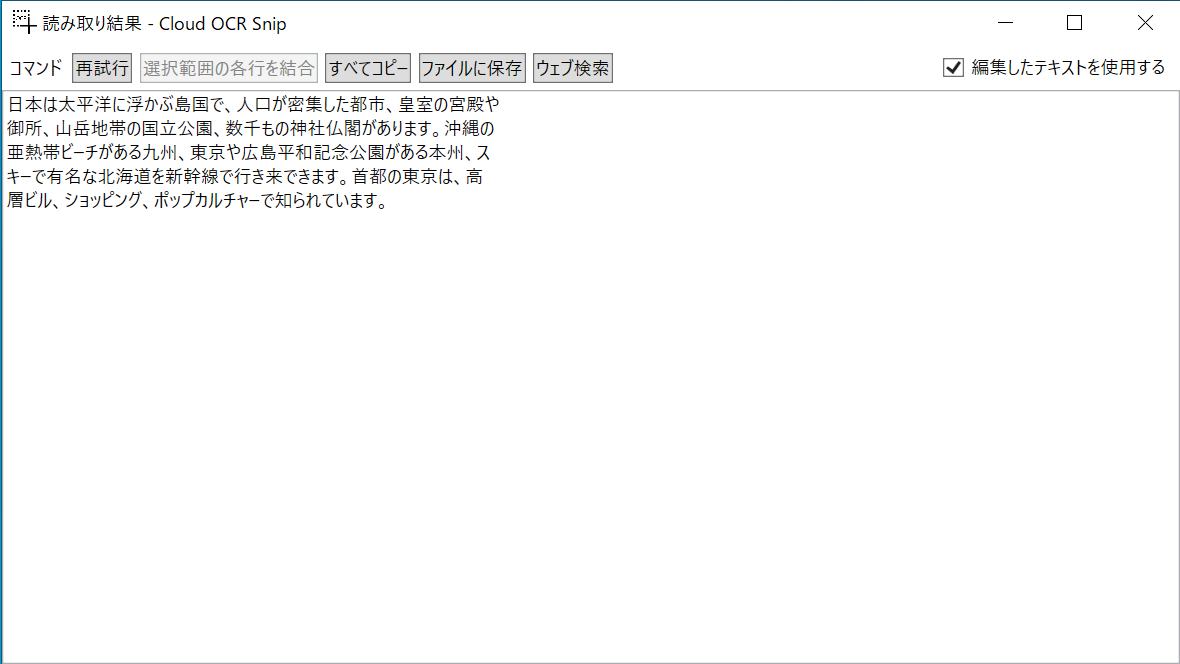
同じ文章を今度はCloud OCR Snipで文字認識させてみます。
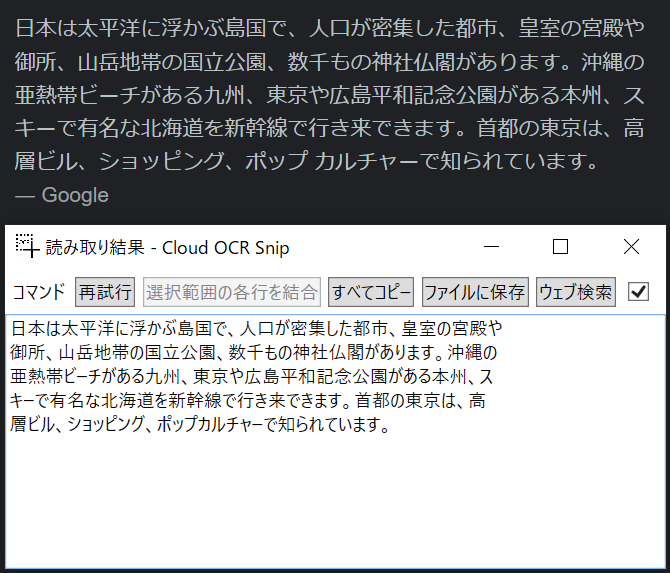
ぱっと見、間違いが見つからない (画像:「日本」の検索結果をCloud OCR Snipで文字認識させた結果)
こちらは一字一句しっかりと読み取れています。
ここまで差が出る理由は、画像の解像度の違いなどではなく、データをクラウドで処理している点にあります。詳しく言うと、撮影した画像をクラウドサービスに送信して、クラウドサービスで分析して返ってきた結果を表示しているためです。
ただそれだけを聞くと、「なぜ画像を処理する場所が変わっただけでこれほど差が出るの?」と疑問を抱くと思います。
それはそれぞれのクラウドサービスが独自技術で認識精度を上げているからなのですが、上の例で使ったクラウドサービスの「Google Cloud Vision API」の場合は以下のようなことを行っていると思われます。
- 世界中の人々が行ったウェブ検索で収集したデータを分析する
- ウェブ上の画像を収集して分析する
- これまでに行った文字認識のデータを分析する
このような文字認識の機能はクラウドサービスによっては完全に有料だったりするんですが、「Google Cloud Vision API」については毎月1000回まで無料です(1000回を超えると1000回ごとに$1.50 (約170円)かかります)。
※上記の情報は2021年12月時点のものです。最新の情報はこちらから確認してください。
また、タスクバーの右にあるアイコンをクリックするかショートカットキーを押すだけで文字認識を始められるので、ちょっと調べたいような時でも手軽に使用できます。
まとめると、Cloud OCR SnipとGoogle Cloud Vision APIを使えば(毎月1000回まで)無料かつ簡単にとても高精度な文字認識を利用できるというわけです。
使い方
細かく説明するためにページを分けました。
インストール・初期設定方法:
https://bigbamboo-jp.hatenablog.com/entry/cos-introduction-2
画面上の文字を読み取る方法:
https://bigbamboo-jp.hatenablog.com/entry/cos-introduction-3
画像ファイルから文字認識する方法:
https://bigbamboo-jp.hatenablog.com/entry/cos-introduction-4